Swift Parser
简介
编译原理中提到,任何一个编译器都要经历三个步骤, 即词法分析, 语法分析, 语义分析。 编程语言经过这三个步骤之后, 将由毫无意义的文本文件变成一系列有用的数据流(token stream), 在软件开发者眼里, 其实这就是将文件进行了反序列化。
编译一个swift需要经历的步骤
首先, 我们先看一幅图: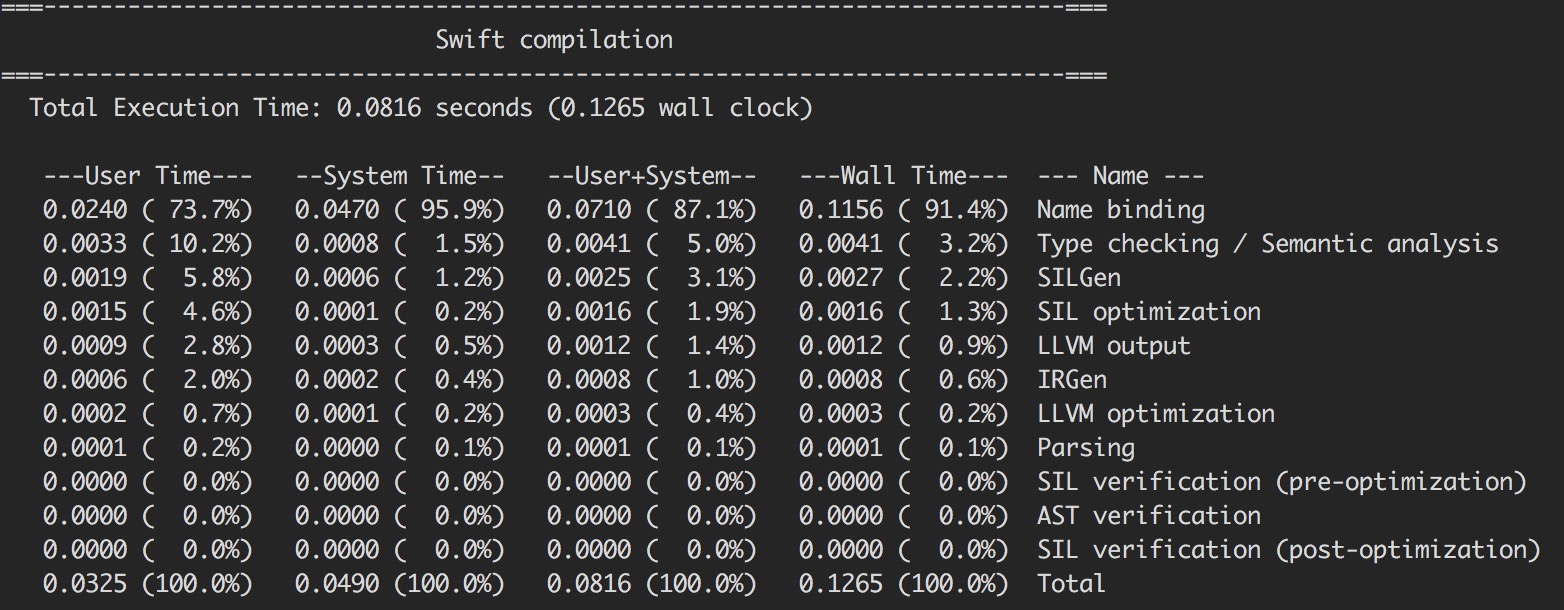
我们看到swift编译器会统计所有的阶段它所花费的时间。从中,我们可以看出, 本篇文章准备分析的parse部分, 大约消耗了0.1%的编译时间。从耗时方面可以基本忽略不计, 之所以在这里要分析parser部分,是因为Parser部分充当了整个swift编译器的“门神”。
Swift中的Parser直观上讲, 大致相当于词法分析。主要的功能是检查当前的swift代码是否有明显的匹配错误。
Swift中的DFA
DFA和NFA最大的区别在于,NFA在接受下一个状态的时候, 可能有多种的处理方式, 因此在匹配发生错误或者不匹配的时候, 需要“吐出”预先吞入的数据。因此对于复杂的程序而言, 这样做的成本太高。针对NFA的种种不是, DFA很好的处理了这些问题, DFA的最主要的特性在于, 每个状态都是唯一的, 不需要再发生错误匹配的时候重新读取或者吐出数据, 当前的状态可以作为任意状态的前缀。
//此处应该有图
swift在做词法分析, 自然也是采用DFA。